Autonomous math agent on Erdős problems
The progress of AI in mathematics has been incredible. In just a few years the models went from struggling with high-school arithmetic, to struggling with AIME problems, to scoring at gold-medal level at the IMO (OpenAI and DeepMind, 2025). Once people realized the models had become good enough to attack open research problems, they started using them on the Erdős problems, a list of open problems of varying difficulty on erdosproblems.com. By far the most striking result, not just among these but anywhere, is the OpenAI model that disproved Erdős’s roughly eighty-year-old unit distance conjecture (OpenAI, paper). It is going to be very exciting, and a little scary, to see where this takes us, even just over the next couple of years.
I got really curious and wanted to try my hand at this too. When the group at Peking University (frenzymath) released Rethlas, the agent they had used to disprove the Anderson conjecture, I wanted to use it to see which Erdős problems we could attack. From what I can tell, most people doing this are working through the OpenAI chat interface, or calling a model like GPT-5.5 directly, mostly one problem at a time. What I wanted to try was different: what happens if you run it at massive scale, attacking many, many problems at once? In this post we share the pipeline for doing this, as well as the results we got.
The runner is open source at github.com/leon2k2k2k/Rethlas, so you can try it yourself: clone it, point it at the problems you care about, and it attacks them. The easiest way to drive it is to open it in an AI coding harness like Claude Code, which reads the included CLAUDE.md and runs the whole workflow for you. The five featured results, with source and PDFs, are on the solutions page.
What is Rethlas
We start by describing what Rethlas is. Rethlas is a generate-and-verify system made of two agents. The generation agent searches the literature, constructs examples and counterexamples, breaks the goal into sub-lemmas, and proves them directly or recursively. Its output is a blueprint, an informal proof written out in structured form: named lemmas and a main theorem, the step-by-step argument for each, and citations to the results it relied on. The verification agent is a separate service you host locally; it takes the blueprint and checks the validity of each step. A blueprint counts as verified only if there are no critical errors and no gaps, and anything short of that is returned as not verified, with the specific errors and gaps handed back as repair hints. The generation agent takes that feedback in a loop, repairing and retrying until the blueprint is verified.
One thing that makes Rethlas stand out is that it is built on Codex: both the generation and the verification agent are Codex agents. Since Codex can be used through a subscription, which gives far more tokens than direct API calls, this lets us do many more runs for a flat fee instead of paying for expensive API calls. That is what makes it somewhat economical to run at scale.
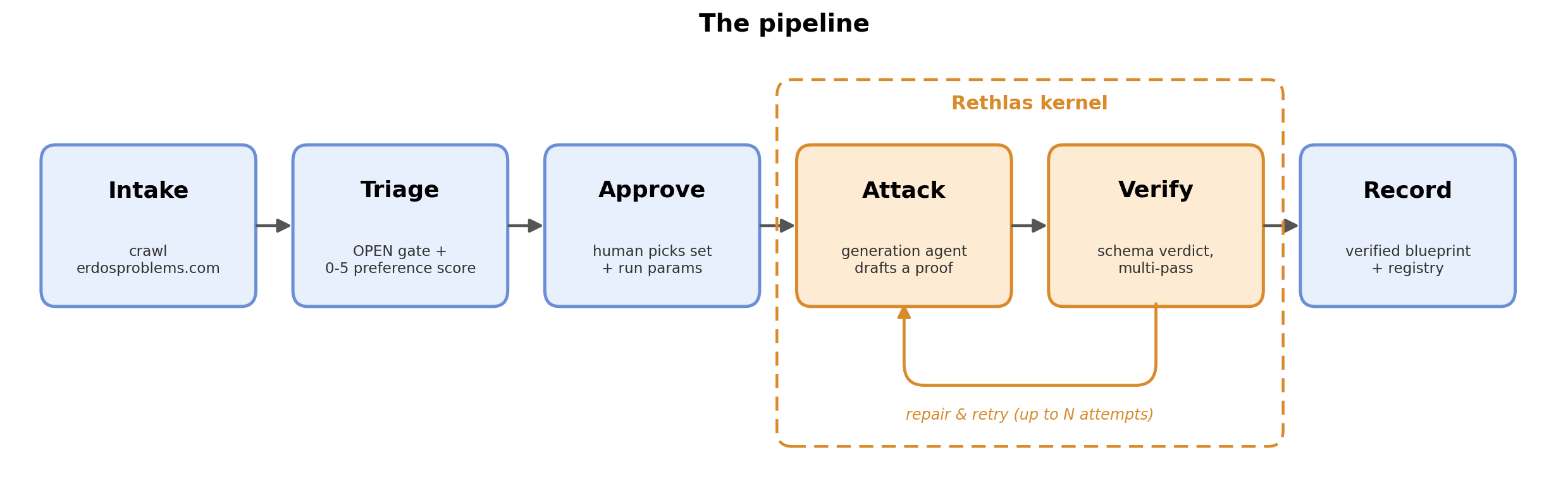
The pipeline
We develop a pipeline whose solver core is Rethlas. To run it at scale you cannot just hand Rethlas one problem after another, since most are not worth the compute, so the real work is in choosing well. It starts by selecting a batch of problems from erdosproblems.com, say everything from #700 to #800. Each one then goes through a triage stage that looks at the problem and asks a few things: is it still open or already closed, has part of it already been solved, and does it look tractable in a single session? It also scores how well the problem matches the kind of thing we care about, which we give it as a short free-form preferences file (for example, “inequalities and improvable bounds”). The triage explains its reasoning for each, reshapes the problem into a clean file, and hands back a ranked shortlist of what it found and what it proposes attacking. We decide which ones to actually run, and the chosen problems are run as a pool of agents whose parameters (the model, reasoning effort, retries per problem, and how many run at once) are ours to set.
To make this concrete, here is how a run goes. Before anything starts, we write what we care about into a short file, preferences.md. For the run we use as the running example, it is just bounds:
# Problem preferences
I prefer inequalities and bounds. If a problem already has a known or partial bound,
that is a feature, not a disqualifier: there is usually room to improve the constant,
tighten the exponent, or settle a special case. Favor bound-improvement targets;
avoid all-or-nothing existence or disproof problems with no incremental foothold.
We point the triage at a range, here problems #700 to #800. It drops anything already settled before any model is called, then scores the remaining open problems from 0 to 5 against that file and sorts them into a tier list; anything scoring 3 or higher becomes a candidate. For #700 to #730, of the thirty-one problems in that range (seventeen still open), it produces:
| Score | Problems |
|---|---|
| 5 | #708, #709 |
| 4 | #700, #704, #706, #710, #719, #725, #726 |
| 3 | (none) |
| 2 | #727, #730 |
| 1 | #701, #711, #712, #713, #714, #724 |
| closed | #702, #703, #705, #707, #715-718, #720-723, #728, #729 |
For the top-tier problems, #708 has a sharp known lower bound and explicit partial lemmas for improving the constant; #709 has CRT/sieve and matching footholds across a wide gap.
We do not need the per-problem reasoning to act on this; we keep the two top tiers, the score-4 and score-5 problems, which leaves nine candidates.
We hand the nine to the pool manager. A run is one campaign config; this one is:
# campaigns/erdos_pool.yaml
mode: pool
concurrency: 5 # problems attacked at once; the queue auto-advances
model: gpt-5.5 # prover + verifier model
reasoning_effort: xhigh # thinking depth
max_attempts: 3 # draft -> verify -> repair cycles per problem
problems: [erdos_708, erdos_709, erdos_700, erdos_704, erdos_706, erdos_710, erdos_719, erdos_725, erdos_726]
python3 pipeline.py pool campaigns/erdos_pool.yaml
Those knobs are the whole control surface. model and reasoning_effort set the model and thinking depth used by both the prover and the verifier. max_attempts is the retry budget: each problem gets up to three full draft -> verify -> repair cycles before we give up on it. concurrency keeps five problems in flight at once. So this run launches all nine problems, five at a time, each in its own isolated workspace, and each one either produces a verified blueprint within three attempts or is dropped.
In practice we rarely drive these steps by hand. Typically an AI agent, for example Claude Code, operates the pipeline end to end: triaging, proposing a shortlist, launching the pool, and reporting the results back to us. To make that easy, the repository ships a memory file (a CLAUDE.md), so an agent like that can pick up the whole workflow with almost no setup.
Novel results
Now we turn to the results. We start with the genuine new partial results we found, one by one.
#819. This is the most original one. A new construction that lifts the classical Erdős–Freud lower bound for the Sidon sumset density f(N)/N from 3/8 = 0.375 to (16√2 − 17)/12 ≈ 0.469, closing most of the gap to the trivial 1/2. The original idea is a reflected two-copy of an asymptotically-maximum Sidon set (a thinned Bose–Chowla set) with a small random shift, analyzed through Pikhurko’s uniformity lemma. This is the most self-standing of the results.
#675(a). A structural super-polynomial lower bound: every translation period of the sums-of-two-squares set exceeds exp(n^c) for every c < 1/10, via a mod-p² lifting argument (small primes p ≡ 3 mod 4 must divide the period) closed off by Linnik’s theorem. This is directly inspired by Ho Boon Suan’s #675(c) result for squarefree numbers, whose strategy carries over.
#301 and #327. Both are the fiber method, pushed past van Doorn’s original argument: #301 sharpens his bound to f(N) ≤ 0.8436N with an exact rational dual certificate, and #327 applies the same machinery to the k-variants (α₁ ≤ 0.7769, α₂ ≤ 0.7630, α₃ ≤ 0.6089). The shared method is the story.
The most interesting one is #153, which comes with a lesson. The question: for a Sidon set A, does the mean of the squared gaps of A+A go to infinity? The agent picked up a shifted-intersection bound Bloom had posted on a related problem and, with it, produced what looked like a full proof. But Bloom had since retracted that bound, so the proof did not hold. What saved a result was that the technique from our #819 work (Pikhurko’s uniformity lemma) carried over and settled the densest case, the asymptotically-maximum Sidon regime where diam(A) is (1+o(1))n²; the intermediate regime stays open. The lesson: the system is finicky, confidently wrong on a borrowed foundation, so every output is a candidate until its proof and citations are checked.
Run breakdown
Across the whole campaign we launched roughly 352 run-attempts. About 21% (74) ended in a verifier-accepted blueprint, about 64% (227) were drafted but rejected by the verifier for gaps or critical errors, and about 14% (51) never produced a usable proof.
Out of those 74, only about five were genuinely new. The reason is how verification works: the generator hands the verifier both the statement it is claiming and a proof, and the verifier only checks that the proof matches that statement, not that the statement is the problem we set out to solve. So on a hard problem the easy way to come back verified is to prove something smaller, a broken-off sub-statement or an easier version. The proof is correct and the verifier is right to accept it, but it does not settle the real question. Most of the 74 are exactly this; a few others are simply wrong in a way the verifier missed.
Comments
We end with a few comments and lessons.
-
We are missing a step after verification that checks whether the verified statement is the full problem or only a sub-problem. If it is only a sub-problem, we can re-run Rethlas with that blueprint already in context, so it continues from there.
-
A UI dashboard during a run would be nice, so we can watch what Rethlas is doing as it goes.
-
The Codex subscription gives us gpt-5.5, not gpt-5.5 Pro, the stronger and much more expensive model most people reach for in math research. So the results here sit on the cheaper tier, a floor rather than a ceiling.
-
By far the easiest way to orchestrate all of this is to drive the repo through a coding harness, using its memory file, which also keeps the whole thing interactive for the user.
Enjoy Reading This Article?
Here are some more articles you might like to read next: