Parameter Golf: Six Weeks to Build the Best LLM
What does a 14% compression improvement actually look like? Both models below were trained on the same dataset, in the same 10 minutes, on the same hardware. The only difference is what the community built in six weeks.
From the FineWeb validation set, same 150-token context fed to both models:
| SP1024 Baseline · 1.22 BPB | Near-SOTA Model · 1.06 BPB | |
|---|---|---|
| “…his driver license and auto insurance had been cancelled in October. This poses a problem for” | the estate, though internalieness to gets the pass. It is a fat check that’s gives ges auto insurance company… that’s a fairyyyyyyyyyyyyyyyyyyyyy | the estate’s creditors who need to work out a payment, especially with the new insurance regulations in october… |
| “…New host Steve Byrnes was feeling his way through this” | season. He had just had a short, bad weekkkkkkkkkkkkkkkkkkkkkkkkkkkkkkkk | season’s show, and while he played one of the best nights of his career at the same time, he hadn’t been able to really shine since the first Nashville game… |
| “…Prosecutors now have until” | Jan. 2, the Supreen House prosecutor sentences on a murded case… Mazzzzaglia… charies’s’’’’’‘ | Dec. 18 to sign off on a case after the new hampshire attorney general’s office says they have more time… |
Prompted with “You are a helpful AI assistant. Please answer the following question.” (not very good at general conversation):
| SP1024 Baseline · 1.22 BPB | Near-SOTA Model · 1.06 BPB | |
|---|---|---|
| “The history of the internet began in the 1960s when” | the Netherlands had established a strong supply of information about the Canadian government and its supply chains. The German government, in its own right, is commonly established as a matter of legal… | the internet became the first electronic commerce tool that was used by many people, including children, to connect online. the internet is now used by more than 3 billion users worldwide… |
| “What is 15 multiplied by 13? Let me work it out:” | 1. 2. 3. 4. 5. 6. 7. 8. 9. 10. 11. 12. 14. 13. 14. 15. 16. 17. 18. 19. 19. 20.1 | 15 multiples 13 have 15, for example, 15, for 1000, 1000, 1000, 1000, 1000, 1000, 1000, 1000 |
| “To bake a chocolate cake, you need flour, eggs, butter, and” | sugar… you need to have an infinite wooden cake. Otherwise, you need to be taken as close to an… | salt… Add 1 tablespoon of flour to 1/4 cup of milk and pour over your cake. Add 1/4 teaspoon of sugar… Cook a lightly toasted chocolate cake. Make cupcakes à 3 |
In March 2026, OpenAI released a public competition with a deceptively simple premise: train the best language model you can, but it has to fit in 16,000,000 bytes, and you only get 10 minutes of training time on 8 H100s. Call it parameter golf: every byte counts, every second counts.
What followed over the next six weeks looked, from the outside, like just another competitive coding challenge. It turned out to be something more: techniques stacking on each other in ways nobody planned, innovations that shouldn’t have worked but did, controversial submissions that looked like miracles, mayhem on the last day, and a photo finish. In the end, starting from a model that produces the gibberish above, the community built one that speaks coherently. Just don’t ask it anything that isn’t in the training data. This post goes through some of the highlights, both the technical and the dramatic.
1. The Competition
At the core of this competition is a simple question: how well can a model predict text?
A language model is, at its heart, a probability distribution over text. Given a sequence of words (or more precisely, tokens) the model assigns a probability to every possible next token. A well-trained model should assign high probability to tokens that actually appear in real text, and low probability to tokens that don’t. Think of it like a well-read person trying to complete sentences. Given “The president signed the ___”, they would confidently predict “bill” or “order” and be surprised by “banana.” A bad model treats every next word as equally likely. A good model has internalized the patterns of language well enough to be right, or at least close, most of the time.
The models in this competition are trained and scored on FineWeb, a large dataset of cleaned web text. The score is computed on a held-out validation slice that the models never see during training. For each token in that slice, we ask: what probability did the model assign to the token that actually appeared? The cost for a single token is $-\log_2 p(t)$, where $t$ is the correct token. If the model is perfectly confident ($p(t) = 1$) it pays zero cost. If it assigns $p(t) = 0.5$, it pays 1 bit. If it assigns $p(t) = 0.01$, it pays about 6.6 bits. The total score is this cost summed across all tokens, normalized by the number of bytes in the original text:
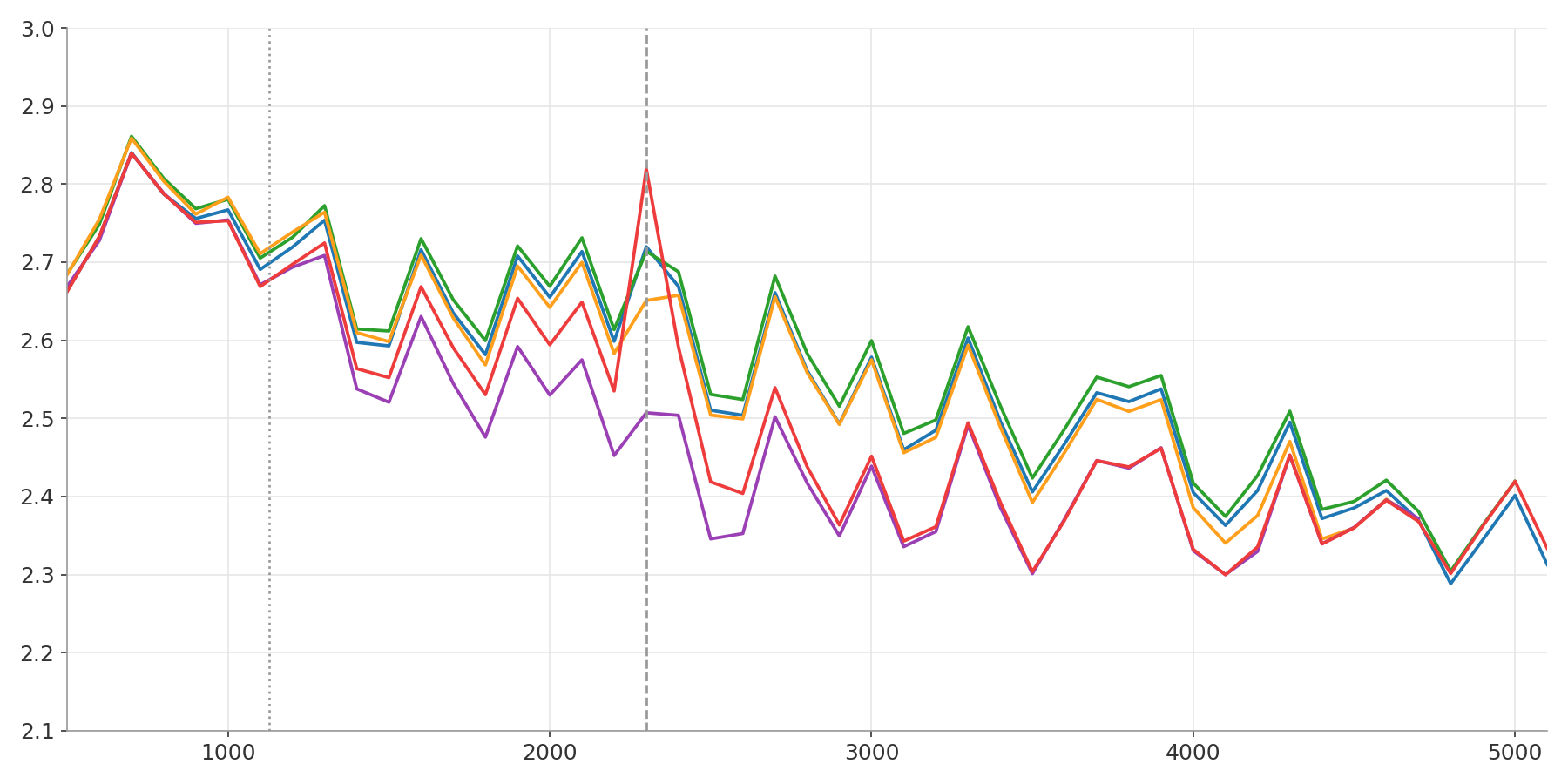
\[\text{BPB} = \frac{-\sum_k \log_2 p(t_k \mid t_1, \ldots, t_{k-1})}{\text{number of bytes}}\]This is called bits-per-byte (BPB). To put it in perspective: a model that assigns completely uniform probability across all 256 possible bytes, knowing nothing at all, scores exactly 8 BPB. The baseline OpenAI provided started at 1.2244 BPB, already far below that, meaning the model had learned real structure in language. Six weeks later, the community had pushed it to 1.0565, a 14% reduction, achieved purely through algorithmic improvements with no change to the hardware or the data.
2. Model Evolution
A modern language model is built from a stack of identical blocks. Each block has two components: attention first, then MLP:
# One transformer block
def block(x):
x = x + attention(x) # tokens communicate: each looks at all others
x = x + mlp(x) # tokens think: each processes what it gathered
return x
# Attention: tokens communicate
def attention(x):
Q = x @ W_Q # what am I looking for?
K = x @ W_K # what do I contain?
V = x @ W_V # what do I share?
weights = softmax(Q @ K.T / sqrt(d))
return weights @ V
# MLP: tokens think
def mlp(x):
return W_2 @ activation(W_1 @ x) # expand, activate, contract
The full model is just these blocks chained one after another:
x → block_1 → block_2 → block_3 → ... → block_N → output
Attention captures how words interact with each other, capturing which tokens are relevant to which. The MLP then enriches the meaning of each token individually, using what attention gathered as context. Each block refines the representation a little further. Stack 9 to 11 of them and you have a language model. We will come back to this picture when we discuss depth recurrence.
The Baseline
OpenAI’s starting model was already not a simple transformer, not a plain stack of attention and MLP blocks. The baseline was more carefully engineered than that. Let’s break it down.
Tokenizer. The baseline used SentencePiece with a 1024-token vocabulary (SP1024), trained on the same FineWeb corpus used for scoring. A 1024-token vocabulary is quite small by modern standards; GPT-2 uses 50,000 tokens. The small vocabulary keeps the embedding table compact, which matters when your entire model has to fit in 16,000,000 bytes.
Model architecture. The baseline was a 9-layer, 512-dimensional transformer with three structural additions worth calling out:
-
U-Net skip connections: in a standard transformer, each layer feeds only into the next. The U-Net pattern adds direct connections that skip the middle of the network. The 9 layers are split into an encoder half (layers 1–4), a bottleneck (layer 5), and a decoder half (layers 6–9). Each decoder layer receives the output of its mirror encoder layer as an additional residual, weighted by a learned scalar w:
# Standard transformer h = block_1(h); h = block_2(h); ...; h = block_9(h) # U-Net: decoder layers receive a skip from their encoder mirror h1 = block_1(h); h2 = block_2(h); h3 = block_3(h); h4 = block_4(h) h5 = block_5(h4) # bottleneck h6 = block_6(h5 + w * h4) # skip from layer 4 h7 = block_7(h6 + w * h3) # skip from layer 3 h8 = block_8(h7 + w * h2) # skip from layer 2 h9 = block_9(h8 + w * h1) # skip from layer 1The early-layer representations, which tend to capture local surface-level patterns, are fed directly into the late layers alongside the deep representations. This is the same idea that made U-Net famous in image segmentation.
-
Grouped-query attention (GQA) and rotary positional embeddings (RoPE), both standard in modern LLMs. GQA shares key-value heads across query heads to cut parameter count; RoPE encodes position by rotating query and key vectors rather than adding learned position embeddings.
Training. The baseline used the Muon optimizer, a popular choice over AdamW. The learning rate follows a warmup-then-warmdown schedule, rising over the first few steps then decaying to zero by the end of the 10-minute window.
Quantization. Every weight in the model is a number stored with some number of bits: more bits means more precision, but also a larger file. After training at bfloat16 (16 bits per weight), the baseline rounded its MLP weights down to int6 (6 bits), shrinking what would otherwise be a ~70 MB model into something that fits the budget. The game is managing the tradeoff: aggressive enough to fit, not so aggressive that predictions degrade. The baseline’s approach was simple: round the biggest chunk of parameters and leave everything else alone.
Post-training adaptation. The baseline did none. During the 10-minute evaluation window, it simply ran the model forward on the validation text and recorded the scores. Later models would use this window to actively update their weights in response to what they were seeing, a technique called test-time training (TTT). The baseline serves as the clean reference point before that complication enters.
This baseline scored 1.2244 BPB. By the end of the competition, the best submission had reached 1.0565 BPB, with the same hardware, the same data, the same 10 minutes, and a model that had been rebuilt almost from scratch across every one of those five components. The rest of this section traces how.
The Evolution
Tokenizer: CaseOps
The vocabulary grew in two steps: SP1024 → SP4096 (PR #1218) → SP8192 (PR #1394). Counterintuitive, since a larger vocabulary means a larger embedding table. The payoff comes from the BPB denominator: it counts bytes, not tokens. A token that encodes two bytes contributes two bytes to the denominator, so a model that packs more bytes per token earns lower BPB for the same prediction quality.
An SP8192 vocabulary still wastes slots on case variants: “the”, “The”, and “THE” are three separate entries. PR #1578 introduced casefold, which lowercases everything before tokenizing, but this permanently destroys casing information the model needs to score correctly. Ruled illegal in Issue #1604.
CaseOps (PR #1729) solved this losslessly. Four control tokens are reserved (TITLE, ALLCAPS, CAPNEXT, ESC) and capitalization is encoded inline:
"The NASA launched." → "TITLE the ALLCAPS nasa launched."
The original text is fully recoverable. The ~8188 remaining vocabulary slots are now entirely free of case duplication, and the control tokens are cheap to predict, since capitalization follows clear patterns, so the model pays very little BPB on them. SP8192+CaseOps remained the tokenizer frontier for the rest of the competition.
Model Architecture: Depth Recurrence and Parallel Residuals
In a standard transformer, each layer runs exactly once per token. PR #1204 first introduced depth recurrence, running middle layers in a loop; later refinements settled on three passes over layers 3–5 as the final topology. The same three layers, the same weights, applied three times in sequence:
standard: 1 → 2 → 3 → 4 → 5 → 6 → 7 → 8 → 9 → 10 → 11
with loop: 1 → 2 → 3 → 4 → 5 → 3 → 4 → 5 → 3 → 4 → 5 → 6 → 7 → 8 → 9 → 10 → 11
└──────────────── ×3 ────────────────┘
17 effective processing steps from 11 physical layers, at zero additional parameter cost. This is free depth: the model gets to think harder without growing larger. The final configuration of 3 passes over layers 3–5 was established in later records.
From layer 8 onward, the final model also runs attention and MLP in parallel rather than sequentially (PR #1204, PR #1529). In a standard block, MLP sees the output of attention. In a parallel block, both branches see the same input and their results are simply added:
# Standard block
x = x + attention(x)
x = x + mlp(x)
# Parallel residual (layers 8–11)
x = x + attention(x) + mlp(x)
This squeezes more computation out of each of the final layers without adding parameters, and the two branches can run simultaneously. Other architectural changes are summarized in the table at the end of this section.
Training: EMA and Loop Curriculum
EMA (PR #287). Instead of evaluating the final checkpoint directly, the model maintains an exponential moving average of all past weight iterates throughout training. The eval model is this running average, not the last step. SGD iterates are noisy; the average sits in a flatter, more stable region of the loss landscape and generalizes significantly better. The decay value introduced in PR #287 was never revisited through the final SOTA.
Loop curriculum (PR #1420). The recurrence loop does not activate from the start of training. For the first 35% of wallclock (~3.5 minutes), the model trains as a standard 11-layer network. The loop then switches on for the remainder. The reason is throughput: 17 effective layers is significantly slower per step than 11. By delaying the loop, the model gets more gradient steps within the 10-minute budget before paying the cost.
The final training run is a well-choreographed 10-minute dance. The learning rate warms up over the first steps, then holds steady for the bulk of training, then warmdowns to a floor as the clock runs down. The loop activates at the 35% mark, shifting the model into its deeper recurrent mode. And towards the end, context grows progressively from 1024 to 2048 to 3072 tokens (PR #2014), giving the model long-range representations right when it needs them most. Every decision is timed to extract the most signal from a budget that ends the moment the last second expires.
Quantization: GPTQ and LQER
Quantization and compression happen after the 10-minute training clock stops, a separate post-processing step before the artifact is sealed. Not everything gets quantized equally. The bulky matrix weights (attention projections, MLP weights, and embeddings) dominate the artifact size and get quantized aggressively (int6 or int7). The small scalar and 1D parameters like gains, skip weights, and mixing coefficients are kept in full precision: they are too sensitive to round safely and too small to matter for the size budget. The baseline rounded MLP weights to int6 using simple nearest-neighbour rounding. The final model does something considerably more sophisticated.
GPTQ (PR #535). When you round a weight, you introduce an error. Instead of ignoring that error, GPTQ compensates for it by adjusting the remaining unquantized weights in the same layer, using second-order information about how sensitive the output is to each weight. The result is a quantized model that stays much closer to the original’s predictions than naive rounding. This evolved to cover all model weights (PR #1285) and embeddings at int7 (PR #1586).
LQER (PR #1797). After GPTQ, some quantization error remains. LQER stores a correction: compute the residual between the original and quantized weights, take a rank-4 low-rank approximation, and pack those correction factors into the artifact. The model reconstructs a better approximation at inference time. The correction costs ~30 KB of artifact space and recovers a meaningful fraction of the remaining quantization damage.
Post-Training: TTT
The final model uses its 10-minute eval window not just for scoring, but to simultaneously adapt its weights to the text it is seeing, a technique called test-time training (TTT). The TTT here splits into two steps:
Per-document LoRA (PR #1530). The base model weights are frozen. For each validation document, a set of low-rank adapter matrices are attached to the model’s projections. The document is processed in chunks: score each chunk first, then take a gradient step to update the adapters. By the final chunk, the model has already adapted to that document’s style and vocabulary. The adapters reset after each document; nothing carries over.
Global SGD phase (PR #1610/#1626). After an initial batch of documents has been scored, a full SGD pass runs on the base model weights themselves, not just the adapters, using all the already-scored documents as training data. The base model is updated, the adapters reset, and the remaining documents are scored on top of this improved base.
The LoRA handles fast local adaptation per document; the global SGD step shifts the base model toward the distribution of the validation set as a whole. The eval budget splits roughly as ~120 seconds for the baseline scoring pass and ~480 seconds for the TTT loop.
Other Changes
Many other techniques were introduced over the six weeks that contributed to the final model. We list some of them here.
| Component | Change | PR |
|---|---|---|
| Architecture | XSA: removes self-copy bias from attention outputs | #265 |
| Architecture | Parallel residuals from layer 8: h = x + Attn(x) + MLP(x) | #1204, #1529 |
| Architecture | SmearGate: learned blend of each token with its neighbor | #65, #1851 |
| Architecture | LeakyReLU² replacing relu² in MLP | #493 |
| Architecture | Partial RoPE + layer-norm scaling | #315 |
| Quantization | AWQ-lite: sensitive weight columns promoted to int8 | #1908 |
| Quantization | Calib32: doubled calibration batches for better Hessian | #2135 |
| Quantization | Artifact compression: lrzip+ZPAQ+L1 row reordering | #1855 |
The final model is a messy, sophisticated combination of all of the above: significant structural innovations layered on top of dozens of smaller refinements, together with countless ablations to find the right hyperparameters for each, each contributing a fraction of the 0.17 BPB gap to the baseline.
3. Too Good to Be True
One might imagine the leaderboard as a steady downward curve from 1.2244 to 1.0565 over six weeks. The reality was anything but. Periodically, a submission would appear claiming a score far below the rest of the field, dropping below 1.0, well beyond what any single technique could explain. Others would quickly follow, stacking on top of the same method, while long threads of debate opened about whether the technique was valid at all. As it turned out, they were all too good to be true. We examine the two most important cases here, and the lesson they leave behind.
N-gram Tilt
An n-gram model tracks token co-occurrence statistics: given the last few tokens, what token tends to come next? The idea behind n-gram tilting (PR #1145) was to run a lightweight n-gram counter alongside the neural model, updated as each token is scored, and use it to boost the probabilities of tokens that the recent history strongly predicts. No extra artifact bytes, no parameters; just a running table built from the document itself.
While the idea is sound, the implementation had a subtle causality issue.1 The within-word and word-start experts had a classic C1 violation (PR #1420):
const uint16_t tok = tokens[i]; // the target token being predicted
const uint8_t is_boundary = boundary_lut[tok];
if (!is_boundary && st->within_len > 0U)
within_valid[i] = 1U; // fire the hint at position i
The gate reads tokens[i] (the token being predicted) before scoring position i. It is like filling in all the answers on an exam, then peeking at the answer key before erasing the wrong ones. A causal system cannot know whether the next token is a continuation token before seeing it. Later on, PR #1514 disable within-word and word-start entirely, keep only the token-order-16 expert. That clean expert survived into the final SOTA.
PPM-D
PPM-D (Prediction by Partial Matching) is the technique behind the PRs with the most impressive claims: scores in the 0.8–1.0 range, far below anything other techniques offered. It is a classical byte-level compression algorithm that counts byte n-grams: given the last few bytes, what byte tends to come next? It is particularly good at within-document repetition. Think of a Russian novel where a character’s long name appears dozens of times; after the first few occurrences, PPM-D can predict the exact spelling almost perfectly, byte by byte. The neural model, by contrast, has no special memory for what has already appeared in this document. The PRs blended PPM-D’s predictions with the neural model’s: an n-byte token with probability p contributing p^(1/n) to each of its byte positions, then mixing with PPM-D. Claimed scores dropped dramatically.
It turned out the math was rigged. A valid probability distribution must sum to exactly 1 (this is C2). For any multi-byte token with p < 1, p^(1/n) > p: the per-byte contributions are inflated, and summing across all tokens that share a given byte gives more than 1.0. In the exam analogy: assigning 90% to each of four answer options simultaneously. The score looked excellent because the scoring formula was fed an invalid distribution. Why the broken math produced such dramatic gains, and why the correct version is actually worse than the baseline, is a more interesting story, explained in PR #1905.2
The Lesson
Both cases point to the same underlying reality. A well-trained language model is already a calibrated entropy estimator: where it predicts a flat distribution, the text really is hard to predict; where it is confident, the text really is predictable.3 The correlation between the model’s uncertainty and the true information content is tight. That is exactly why PPM-D and n-gram statistics could not deliver incredible gains. They were identifying the same easy tokens the model already had low entropy on. For an external signal to genuinely help, its errors would need to be uncorrelated with the model’s: it would need to be uncertain where the model is confident, and vice versa.
There is no silver bullet. The progress that held was incremental, compounding, and hard-won, one careful PR at a time.
4. Drama on the Last Day
This competition did not go quietly. On April 30th, the day before the competition closed, PR #2014 dropped at 1.0576 BPB, a clean record built on the new idea of progressive context scheduling. The field had been grinding toward this number for weeks. Shortly after, a flurry of PRs appeared beating it: 1.047 (a 0.011 gap), 1.043 (a 0.015 gap), numbers that seemed implausibly good.
However, the reason turned out to be nothing anyone had anticipated. prepare_caseops_data.py (the script everyone had been copying to build CaseOps datasets since PR #1736) defaulted to --val-docs=10000. Training started at document 10,000, when it should have started at 50,000. What’s wrong with that? The validation set covers documents 0 through 49,999. Starting training at 10,000 meant that 40,000 out of 50,000 validation documents, eighty percent of which, had been in the training data the whole time. It is like giving students the test questions as homework to prepare for the exam.
Many PRs were eventually classified as leaky (Issue #2127), most of their authors having inherited the data setup from earlier submissions without knowing. As it turned out, the bug had been caught and quietly fixed eight days earlier, then accidentally reintroduced on the very same day. The person who first discovered and patched it was also the one sitting at the top of the leaderboard with that 1.043 score.
With the leaky PRs disqualified, #2014 was restored as the clean SOTA, and with a full day still left on the clock, the door was wide open. A last-hour flurry of clean PRs came in, each trying to be the one to beat it. When the dust settled, one did: PR #2135 at 1.0565 BPB, by a margin of just 0.001. One clean submission, one narrow margin, one number that stood.
Six weeks, two thousand pull requests, and a 14% improvement wrung out of the same hardware, the same data, the same ten minutes, through nothing but engineering. One default flag nearly rewrote the ending. Two methods that looked like miracles turned out to be mistakes. And in the end, what remained was a small, sophisticated model built from a careful accumulation of every technique described above.
-
The competition launched without a complete ruleset. As participants found increasingly creative ways to improve their scores, four constraints were codified mid-competition through community discussion in Issue #1017: C1 (causal eval): the probability assigned to token tₖ must depend only on the tokens before it, never the token itself; C2 (normalized distribution): the output must be a valid probability distribution summing to exactly 1; C3 (score before update): in TTT, a chunk must be fully scored before any gradient step is applied to it; C4 (single pass): each token is scored exactly once. ↩
-
The correct way to convert token probabilities to byte probabilities is to sum over all tokens that share the same byte prefix, weighted by their probabilities. When counted correctly, it turns out that PPM-D yields no gain over the neural model alone. The deeper reason is discussed in the lesson below. ↩
-
The expected entropy at a position is $H = -\sum_t p(t) \log_2 p(t)$, where the sum is over all possible next tokens. This measures how spread out the model’s distribution: high entropy means the model is uncertain; low entropy means it is confident. A well-calibrated model’s expected entropy correlates tightly with the actual information content of the text at that position. ↩
Enjoy Reading This Article?
Here are some more articles you might like to read next: