-
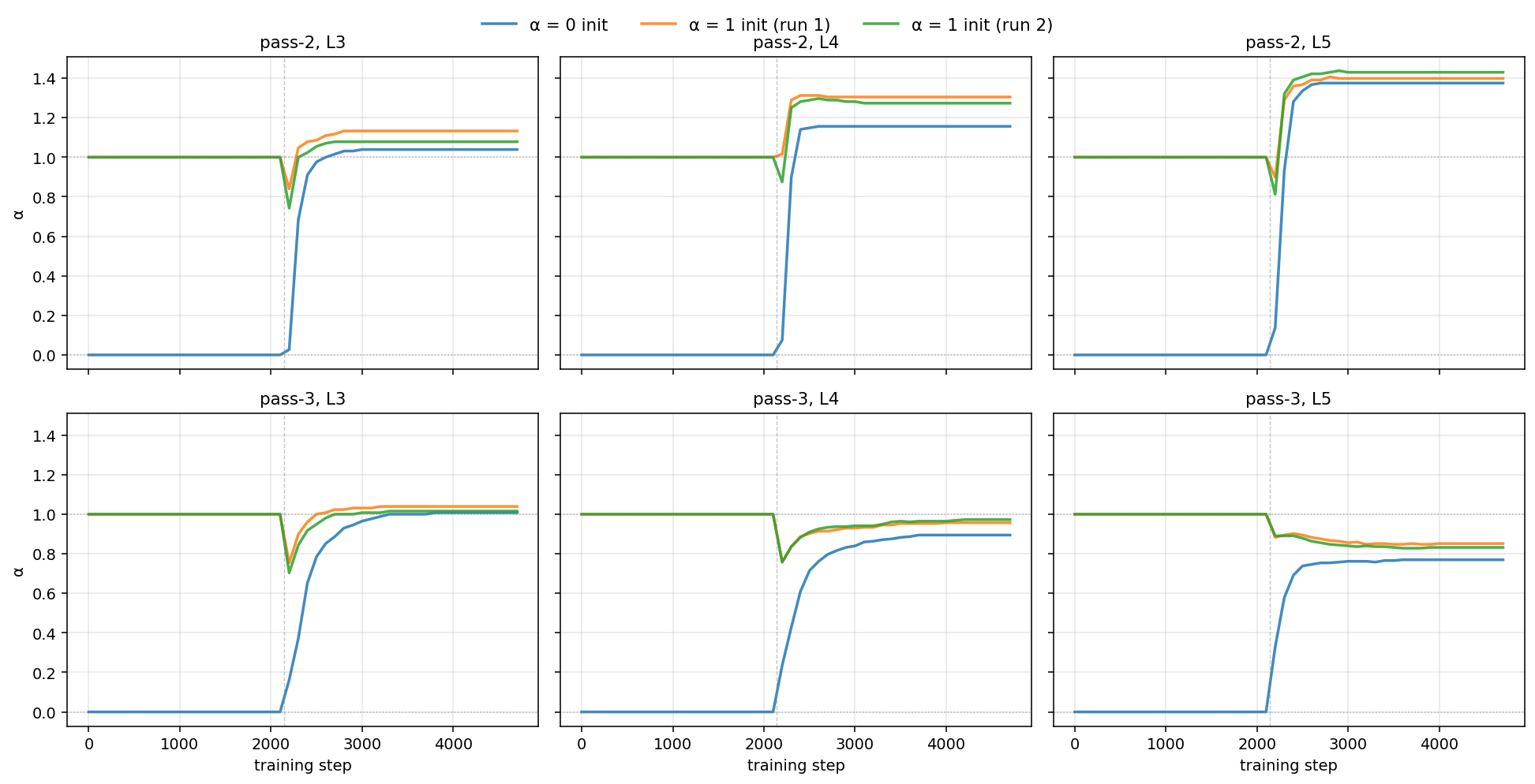
Improving one small model: a deep look at depth-recurrence in 10-minute pretraining
We take one depth-recurrent language model from a 10-minute pretraining competition and try three ways to improve it. Two fail cleanly; the third, learning a mixing rule and then freezing it, ships.
-
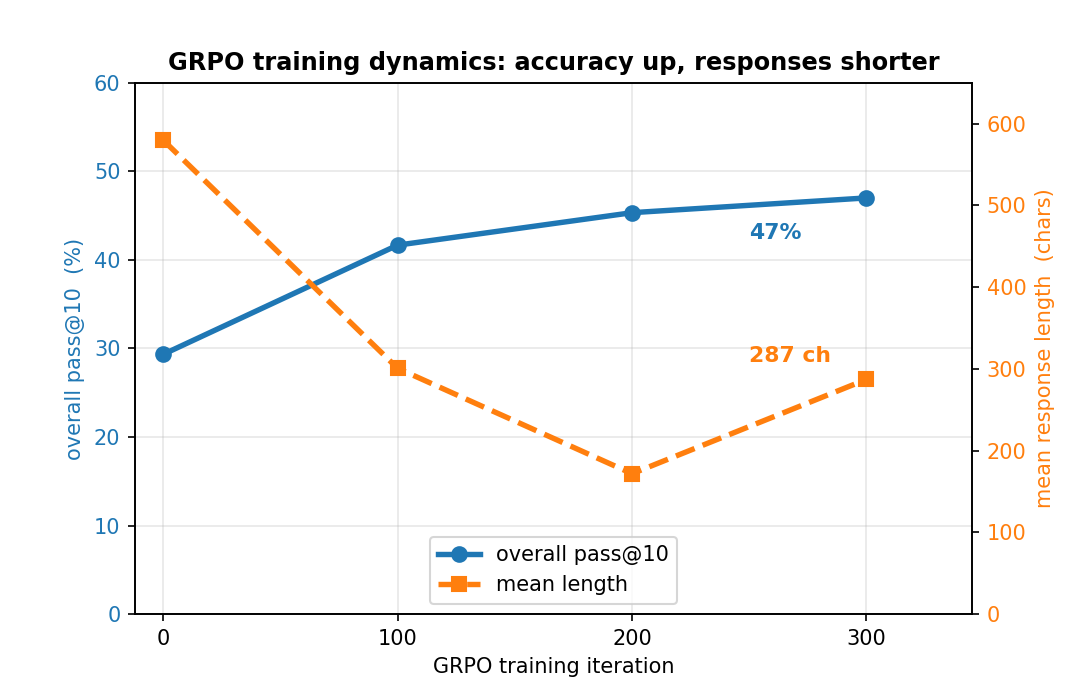
GRPO, SFT, and teaching reasoning through arithmetic
What GRPO and SFT can and cannot teach a 3B model about arithmetic reasoning, measured on the Countdown task.
-
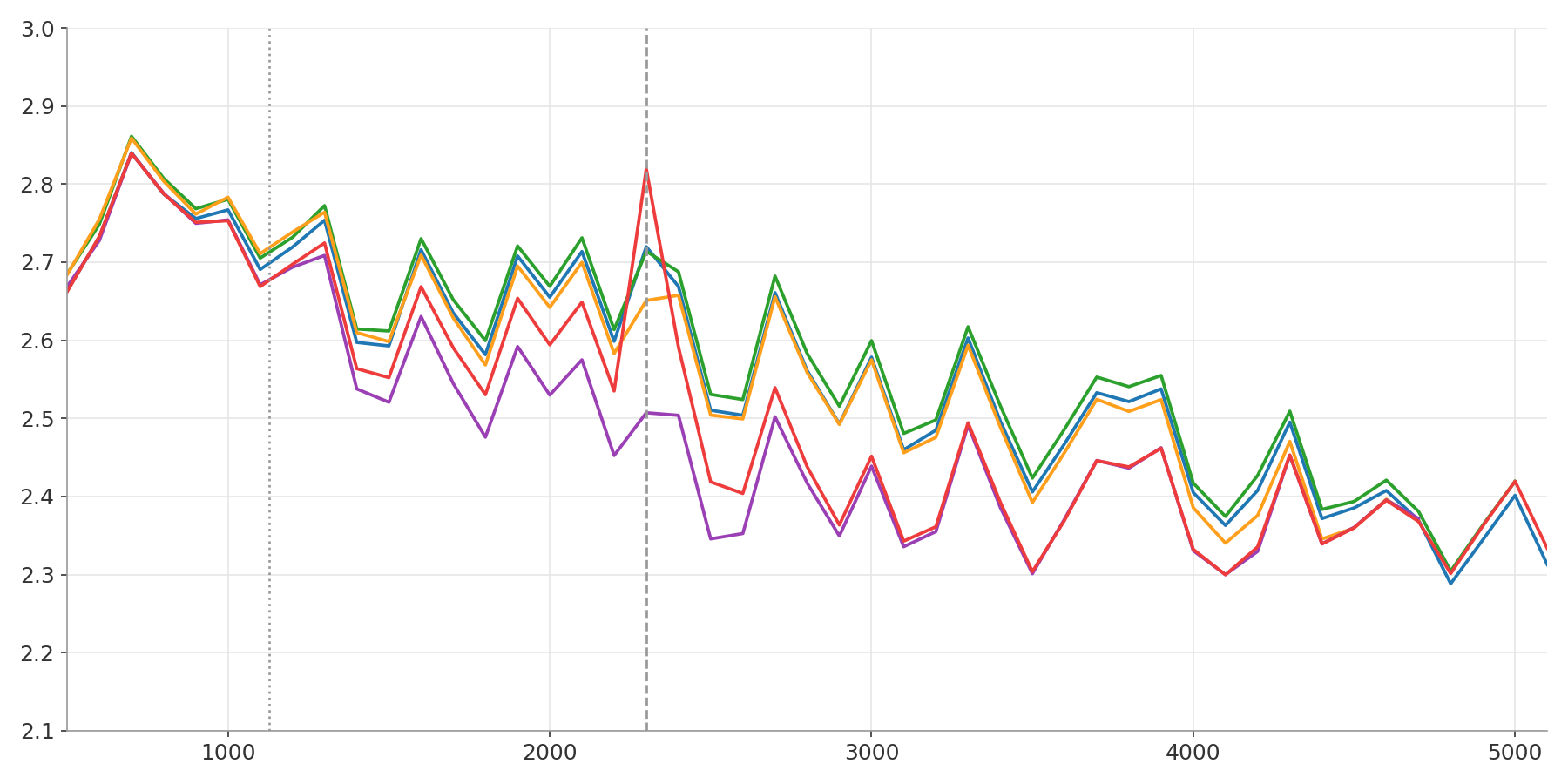
Parameter Golf: Six Weeks to Build the Best LLM
An account of OpenAI's Parameter Golf competition. Six weeks, two thousand pull requests, and a 14% compression improvement wrung from the same hardware, the same data, and the same ten minutes of training.
-
From one 11 to another in four dimension
-
RG flow of 4D gauge theory